
El articulo anterior le ha brindado una descripción general sobre Hadoop y los dos componentes de Hadoop que son HDFS y el marco Mapreduce. Este artículo ahora le brindará una breve explicación sobre la arquitectura HDFS y su funcionamiento.
HDFS:
El sistema de archivos distribuido Hadoop (HDFS) es un almacenamiento en clúster de gran ancho de banda y autorreparación. HDFS tiene una arquitectura maestro/esclavo. Un clúster HDFS consta de un único NameNode, un servidor maestro que administra el espacio de nombres del sistema de archivos y regula el acceso a los archivos por parte de los clientes. Además, hay varios nodos de datos, generalmente uno por nodo en el clúster, que administra el almacenamiento adjunto a los nodos en los que se ejecutan.
HDFS expone un espacio de nombres del sistema de archivos y permite que los datos del usuario se almacenen en archivos. Internamente, un archivo se divide en uno o más bloques y estos bloques se almacenan en un conjunto de DataNodes. NameNode ejecuta operaciones de espacio de nombres del sistema de archivos, como abrir, cerrar y cambiar el nombre de archivos y directorios.
También determina el mapeo de bloques a DataNOdes. Los DataNodes son responsables de atender las solicitudes de lectura y escritura de los clientes del sistema de archivos. Los DataNodes también realizan la creación, eliminación y replicación de bloques según las instrucciones del NameNode.
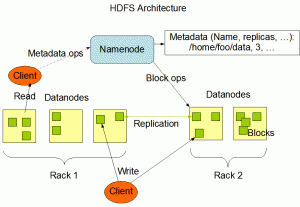
El boceto anterior representa la arquitectura de HDFS.
Mapa reducido:
El otro concepto y componente de Hadoop es Mapreduce. Mapreduce es una gestión y programación de recursos distribuida y tolerante a fallos junto con una abstracción de programación de datos escalable.
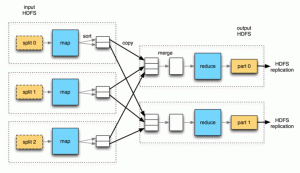
Es un marco de procesamiento de datos paralelo. El marco Mapreduce se utiliza para obtener los datos de los distintos archivos y nodos de datos disponibles en un sistema. La primera parte es que los datos deben enviarse a los diferentes servidores donde se replicarían los archivos; en resumen, se almacena el datos.
El segundo paso, una vez que se almacenan los datos, es enviar el código al clúster de Hadoop al nodo de nombre, que se distribuirá en diferentes nodos de datos que se convertirán en nodos de cálculo y luego el usuario final recibirá el resultado final.
Mapreduce en Hadoop no es solo una función, hay diferentes tareas involucradas como lector de registros, mapa, combinador, particionador, barajar y ordenar y reducir los datos y finalmente proporciona el resultado. Divide el conjunto de datos de entrada en fragmentos independientes que las tareas del mapa procesan de forma completamente paralela.
El marco clasifica los resultados de los mapas, que luego se envían como entrada para las tareas reducidas. Normalmente, tanto la entrada como la salida del trabajo se almacenan en un sistema de archivos. El marco también se encarga de la programación, monitoreándolas y volviendo a ejecutar las tareas fallidas.
Mapreduce Par clave-valor:
Los mapeadores y reductores siempre usan pares clave-valor como entrada y salida. Un reductor reduce los valores por clave únicamente. Un asignador o reductor puede emitir 0,1 o más pares de valores clave para cada entrada. Los mapeadores y reductores pueden emitir claves o valores arbitrarios, no solo subconjuntos o transformaciones de los de la entrada.
Ejemplo:
def mapa (clave, valor, contexto)
value.to_s.split.each hacer |palabra|
palabra.gsub!(/W/, ”)
palabra.downcase!
a menos que palabra.vacía?
contexto.write(Hadoop::Io::Text.new(palabra), Hadoop::Io::IntWritable.new(1))
fin
fin
fin
def reducir (clave, valores, contexto)
suma = 0
valores.cada uno { |valor| suma += valor.get }
contexto.write(clave, Hadoop::Io::IntWritable.new(suma))
fin
El método Mapper divide en espacios en blanco, elimina todos los caracteres que no son palabras y las minúsculas. Genera un uno como valor. El método reductor consiste en iterar sobre los valores, sumar todos los números y generar la clave de entrada y la suma.
Fichero de entrada: Hola mundo, adiós mundo.
archivo de salida: Adiós 1
hola 1
Mundo 2
Aquí termina la sesión informativa sobre los componentes de Hadoop, su arquitectura, funcionamiento y también los pasos involucrados en los diferentes procesos que suceden en ambos sistemas de Hadoop.
También hay algunos pros y contras de Hadoop, similar a una moneda que consta de dos caras, que se discutirán en los próximos blogs. El conocimiento completo de cualquier concepto sólo será posible una vez que se conozcan las ventajas y desventajas de ese concepto en particular.
De ahora en adelante para adquirir un conocimiento completo de Hadoop sigue las próximas publicaciones del blog.
Las dos caras de Hadoop
Ventajas:
- Hadoop es una plataforma que proporciona almacenamiento distribuido y capacidades computacionales.
- Hadoop es extremadamente escalable. De hecho, Hadoop fue el primero en considerarse para solucionar un problema de escalabilidad que existía en Nutch: comience con 1 TB/3 nodos y crezca hasta petabytes/miles de nodos.
- Uno de los componentes principales de Hadoop es HDFS (el componente de almacenamiento) que está optimizado para un alto rendimiento.
- HDFS utiliza tamaños de bloques grandes que, en última instancia, ayudan. Funciona mejor cuando se manipulan archivos grandes (gigabytes, petabytes…).
- La escalabilidad y la disponibilidad son las características distinguidas de HDFS para lograr la replicación de datos y el sistema de tolerancia a fallas.
- HDFS puede replicar archivos una cantidad específica de veces (el valor predeterminado es 3 réplicas) que es tolerante a fallas de software y hardware. Además, puede volver a replicar automáticamente bloques de datos en nodos que han fallado.
- Hadoop utiliza el marco MapReduce, que es un marco informático distribuido basado en lotes que permite el trabajo en paralelo sobre una gran cantidad de datos.
- MapReduce permitió a los desarrolladores centrarse únicamente en abordar las necesidades comerciales, en lugar de involucrarse en las complicaciones del sistema distribuido.
- Para lograr una ejecución paralela y más rápida del trabajo, MapReduce descompone el trabajo en tareas de Map & Reduce y las programa para su ejecución remota en los nodos esclavos o de datos del Hadoop Cluster.
- Hadoop tiene la capacidad de trabajar con trabajos de MR creados en otros idiomas: se llama streaming
- adecuado para analizar big data
- El S3 de Amazon es la última fuente de verdad aquí y HDFS es efímero. No tiene que preocuparse por la confiabilidad, etc.: Amazon S3 se encarga de eso por usted. También significa que no necesita un factor de replicación alto en HDFS.
- Puede aprovechar funciones de archivo interesantes como Glacier.
- También paga por el cálculo solo cuando lo necesita. Es bien sabido que la mayoría de las instalaciones de Hadoop tienen dificultades para alcanzar incluso la utilización de 40% [3],[4]. Si su utilización es baja, poner en marcha clústeres bajo demanda puede ser una buena opción para usted.
- Otro punto clave es que sus cargas de trabajo pueden tener algunos picos (por ejemplo, al final de la semana o del mes) o pueden estar creciendo cada mes. Puede lanzar clústeres más grandes cuando lo necesite y, de lo contrario, quedarse con los más pequeños.
- No es necesario que esté preparado para la carga de trabajo máxima todo el tiempo. De manera similar, no es necesario planificar su hardware con 2 o 3 años de anticipación, como es la práctica común con los clústeres internos. Puedes pagar sobre la marcha, crecer como quieras. Esto reduce considerablemente el riesgo que implican los proyectos de Big Data.
- Sus costos de administración pueden ser significativamente menores, reduciendo su TCO.
- Sin costos iniciales de equipo. Puede activar tantos nodos como desee, durante el tiempo que los necesite, y luego apagarlos. Cada vez es más fácil ejecutar Hadoop en ellos.
- Economía: costo por TB en una fracción de las opciones tradicionales.
- Flexibilidad: almacene cualquier dato, ejecute cualquier análisis.
contras:
- Como sabe, Hadoop usa HDFS y MapReduce. Ambos procesos maestros son puntos únicos de falla, aunque se está trabajando activamente para las versiones de alta disponibilidad.
- Hasta el lanzamiento de Hadoop 2.x, HDFS y MapReduce utilizarán modelos de maestro único que pueden resultar en puntos únicos de falla.
- La seguridad también es una de las principales preocupaciones porque Hadoop ofrece un modelo de seguridad, pero de forma predeterminada está deshabilitado debido a su alta complejidad.
- Hadoop no ofrece almacenamiento ni cifrado a nivel de red, lo cual es una gran preocupación para los datos de aplicaciones del sector gubernamental.
- HDFS es ineficiente para manejar archivos pequeños y carece de compresión transparente. Dado que HDFS no está diseñado para funcionar bien con lecturas aleatorias de archivos pequeños debido a su optimización para un rendimiento sostenido.
- MapReduce es una arquitectura basada en lotes, lo que significa que no se presta a casos de uso que necesiten acceso a datos en tiempo real.
- MapReduce es una arquitectura sin compartir, por lo que las tareas que requieren sincronización global o intercambio de datos mutables no son una buena opción, lo que puede plantear desafíos para algunos algoritmos.
- S3 no es muy rápido y el rendimiento S3 de Apache Hadoop básico no es excelente. Nosotros, en Qubole, hemos trabajado un poco en el rendimiento de Hadoop con el sistema de archivos S3.
- S3, por supuesto, viene con su propio coste de almacenamiento.
- Si desea conservar las máquinas (o los datos) durante mucho tiempo, no es una solución tan económica como un clúster físico.
Aquí termina la sesión informativa de Grandes datos y Hadoop y sus diversos sistemas y sus pros y contras. Ojalá hubieras tenido una visión general sobre el concepto de Big Data y Hadoop.
Póngase en contacto con nosotros.
Manasa Heggere
Desarrollador senior Ruby on Rails



