
L'article précédent vous a donné un aperçu de Hadoop et des deux composants de Hadoop qui sont HDFS et le framework Mapreduce. Cet article va maintenant vous donner une brève explication sur l'architecture HDFS et son fonctionnement.
HDFS :
Le système de fichiers distribués Hadoop (HDFS) est un stockage en cluster à large bande passante auto-réparateur. HDFS a une architecture maître/esclave. Un cluster HDFS est constitué d'un seul NameNode, un serveur maître qui gère l'espace de noms du système de fichiers et régule l'accès aux fichiers par les clients. De plus, il existe un certain nombre de nœuds de données, généralement un par nœud dans le cluster, qui gèrent le stockage attaché aux nœuds sur lesquels ils s'exécutent.
HDFS expose un espace de noms de système de fichiers et permet de stocker les données utilisateur dans des fichiers. En interne, un fichier est divisé en un ou plusieurs blocs et ces blocs sont stockés dans un ensemble de DataNodes. Le NameNode exécute des opérations d'espace de noms du système de fichiers telles que l'ouverture, la fermeture et le renommage de fichiers et de répertoires.
Il détermine également le mappage des blocs vers DataNOdes. Les DataNodes sont chargés de répondre aux demandes de lecture et d'écriture des clients du système de fichiers. Les DataNodes effectuent également la création, la suppression et la réplication de blocs sur instruction du NameNode.
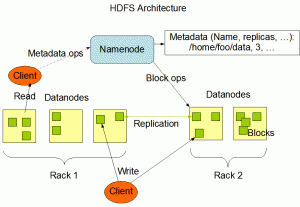
Le croquis ci-dessus représente l'architecture du HDFS.
MapRéduire :
L'autre concept et composant de Hadoop est Mapreduce. Mapreduce est une gestion et une planification distribuées des ressources tolérantes aux pannes, couplées à une abstraction de programmation de données évolutive.
Il s'agit d'un cadre de traitement de données parallèle. Le framework Mapreduce est utilisé pour extraire les données des différents fichiers et nœuds de données disponibles dans un système. La première partie est que les données doivent être poussées sur les différents serveurs où les fichiers seraient répliqués, en bref, il s'agit de stocker les données. données.
La deuxième étape, une fois les données stockées, le code doit être poussé sur le cluster Hadoop vers le nœud de nom qui serait distribué sur différents nœuds de données qui deviendraient les nœuds de calcul, puis l'utilisateur final recevrait le résultat final.
Mapreduce dans Hadoop n'est pas seulement la seule fonction en cours, différentes tâches sont impliquées comme le lecteur d'enregistrement, la carte, le combinateur, le partitionneur, la lecture aléatoire, le tri et la réduction des données et enfin donne le résultat. Il divise l'ensemble de données d'entrée en morceaux indépendants qui sont traités par les tâches cartographiques de manière complètement parallèle.
Le framework trie les sorties des cartes, qui sont ensuite poussées comme entrée dans les tâches réduites. Généralement, l'entrée et la sortie du travail sont stockées dans un système de fichiers. Le framework s'occupe également de la planification, en les surveillant et en réexécutant les tâches ayant échoué.
Paire clé-valeur Mapreduce :
Les mappeurs et les réducteurs utilisent toujours des paires clé-valeur comme entrée et sortie. Un réducteur réduit les valeurs par clé uniquement. Un mappeur ou un réducteur peut émettre 0,1 ou plusieurs paires clé-valeur pour chaque entrée. Les mappeurs et les réducteurs peuvent émettre des clés ou des valeurs arbitraires, pas seulement des sous-ensembles ou des transformations de celles de l'entrée.
Exemple:
def map (clé, valeur, contexte)
value.to_s.split.each faire |word|
mot.gsub!(/W/, ")
mot.downcase!
à moins que mot.vide ?
contexte.write(Hadoop::Io::Text.new(word), Hadoop::Io::IntWritable.new(1))
fin
fin
fin
def réduire (clé, valeurs, contexte)
somme = 0
valeurs.each { |valeur| somme += valeur.get }
contexte.write(clé, Hadoop::Io::IntWritable.new(sum))
fin
La méthode Mapper se divise en espaces, supprime tous les caractères autres que des mots et les minuscules. Il génère un un comme valeur. La méthode de réduction consiste à parcourir les valeurs, à additionner tous les nombres et à afficher la clé d'entrée et la somme.
Fichier d'entrée : Bonjour le monde, au revoir le monde
fichier de sortie: Au revoir 1
Bonjour 1
Monde 2
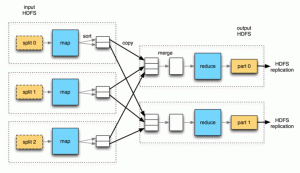
Ainsi se termine le briefing sur les composants de Hadoop, leur architecture, leur fonctionnement ainsi que les étapes impliquées dans les différents processus se déroulant dans les deux systèmes de Hadoop.
Il y a aussi quelques avantages et inconvénients de Hadoop, tout comme une pièce composée de deux faces, qui seront discutés dans les prochains blogs. Une connaissance complète de n’importe quel concept n’est possible qu’une fois que vous connaissez les avantages et les inconvénients d’un concept particulier.
Désormais pour acquérir une connaissance complète de Hadoop, continuez à suivre les prochains articles du blog.
Les deux visages de Hadoop
Avantages:
- Hadoop est une plate-forme qui offre à la fois des capacités de stockage distribué et de calcul.
- Hadoop est extrêmement évolutif. En fait, Hadoop a été le premier à être envisagé pour résoudre un problème d'évolutivité qui existait dans Nutch : commencer à 1 To/3 nœuds et atteindre des pétaoctets/1 000 nœuds.
- L'un des composants majeurs de Hadoop est HDFS (le composant de stockage) optimisé pour un débit élevé.
- HDFS utilise des blocs de grande taille, ce qui en fin de compte fonctionne mieux lors de la manipulation de fichiers volumineux (gigaoctets, pétaoctets…).
- L'évolutivité et la disponibilité sont les caractéristiques distinctives de HDFS pour réaliser la réplication des données et le système de tolérance aux pannes.
- HDFS peut répliquer des fichiers un nombre de fois spécifié (la valeur par défaut est 3 répliques), ce qui tolère les pannes logicielles et matérielles. De plus, il peut répliquer automatiquement les blocs de données sur les nœuds en panne.
- Hadoop utilise le framework MapReduce qui est un framework informatique distribué par lots. Il permet un travail en parallèle sur une grande quantité de données.
- MapReduce permet aux développeurs de se concentrer uniquement sur la réponse aux besoins de l'entreprise, plutôt que de s'impliquer dans les complications des systèmes distribués.
- Pour obtenir une exécution parallèle et plus rapide du travail, MapReduce décompose le travail en tâches Map & Reduction et les planifie pour une exécution à distance sur l'esclave ou les nœuds de données du cluster Hadoop.
- Hadoop a la capacité de travailler avec des tâches MR créées dans d'autres langues – c'est ce qu'on appelle le streaming.
- adapté à l’analyse du big data
- Le S3 d'Amazon est ici la source ultime de vérité et HDFS est éphémère. Vous n'avez pas à vous soucier de la fiabilité, etc. – Amazon S3 s'en charge pour vous. Cela signifie également que vous n'avez pas besoin d'un facteur de réplication élevé dans HDFS.
- Vous pouvez profiter de fonctionnalités d’archivage intéressantes comme Glacier.
- Vous payez également pour le calcul uniquement lorsque vous en avez besoin. Il est bien connu que la plupart des installations Hadoop ont du mal à atteindre même l'utilisation du 40% [3],[4]. Si votre utilisation est faible, la création de clusters à la demande peut être une solution gagnante pour vous.
- Un autre point clé est que vos charges de travail peuvent connaître des pics (par exemple en fin de semaine ou de mois) ou augmenter chaque mois. Vous pouvez lancer des clusters plus grands lorsque vous en avez besoin et vous en tenir à des clusters plus petits sinon.
- Vous n’êtes pas obligé de prévoir en permanence une charge de travail de pointe. De même, vous n'avez pas besoin de planifier votre matériel 2 à 3 ans à l'avance, comme c'est une pratique courante avec les clusters internes. Vous pouvez payer au fur et à mesure, grandir à votre guise. Cela réduit considérablement les risques liés aux projets Big Data.
- Vos coûts d’administration peuvent être considérablement réduits, réduisant ainsi votre TCO.
- Pas de frais d’équipement initiaux. Vous pouvez démarrer autant de nœuds que vous le souhaitez, aussi longtemps que vous en avez besoin, puis l'arrêter. Il est de plus en plus facile d'exécuter Hadoop sur eux.
- Aspects économiques – Coût par To à une fraction des options traditionnelles.
- Flexibilité – Stockez toutes les données, exécutez n'importe quelle analyse.
les inconvénients:
- Comme vous le savez, Hadoop utilise HDFS et MapReduce, leurs deux processus maîtres sont des points de défaillance uniques, bien qu'un travail actif soit en cours pour les versions haute disponibilité.
- Jusqu'à la version Hadoop 2.x, HDFS et MapReduce utiliseront des modèles à maître unique, ce qui peut entraîner des points de défaillance uniques.
- La sécurité est également l'une des préoccupations majeures car Hadoop propose un modèle de sécurité. Mais celui-ci est désactivé par défaut en raison de sa grande complexité.
- Hadoop n'offre pas de chiffrement au niveau du stockage ou du réseau, ce qui constitue une très grande préoccupation pour les données des applications du secteur gouvernemental.
- HDFS est inefficace pour gérer les petits fichiers et manque de compression transparente. Comme HDFS n'est pas conçu pour fonctionner correctement avec des lectures aléatoires sur de petits fichiers en raison de son optimisation pour un débit soutenu.
- MapReduce est une architecture basée sur des lots, ce qui signifie qu'elle ne se prête pas aux cas d'utilisation nécessitant un accès aux données en temps réel.
- MapReduce est une architecture sans partage. Par conséquent, les tâches qui nécessitent une synchronisation globale ou le partage de données mutables ne conviennent pas, ce qui peut poser des défis à certains algorithmes.
- S3 n'est pas très rapide et les performances S3 d'Apache Hadoop vanille ne sont pas excellentes. Chez Qubole, nous avons travaillé sur les performances de Hadoop avec le système de fichiers S3.
- Bien entendu, S3 a son propre coût de stockage.
- Si vous souhaitez conserver les machines (ou les données) pendant une longue période, ce n'est pas une solution aussi économique qu'un cluster physique.
Ici se termine le briefing de Big Data et Hadoop et ses différents systèmes et leurs avantages et inconvénients. J'aurais aimé avoir un aperçu du concept du Big Data et de Hadoop.
Manasa Heggere
Développeur senior Ruby on Rails



